
Mysql索引
官方文档https://dev.mysql.com/doc/refman/5.7/en/indexes.html
一 什么是索引
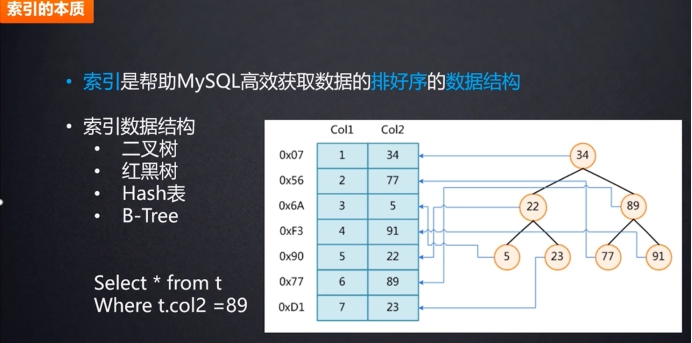
索引是帮助mysql高效获取数据的排好序的数据结构。
二 索引结构
1.1二叉树
二叉树,每个节点是一个key-value键值对,key存放该行数据的索引顺序,value存放该行数据在内存中的地址指针。
二叉树的结构,左边的节点元素的key值,永远小于右边的节点元素的key值,因此形成了如同下图的一种树结构。
查询顺序,比如说查询col2为23的数据,会从顶级节点34开始查找,然后逐层向下对比,经过3次I/O 能查询出数据。如果不使用二叉树索引,则需要查询7次才能查询到数据。
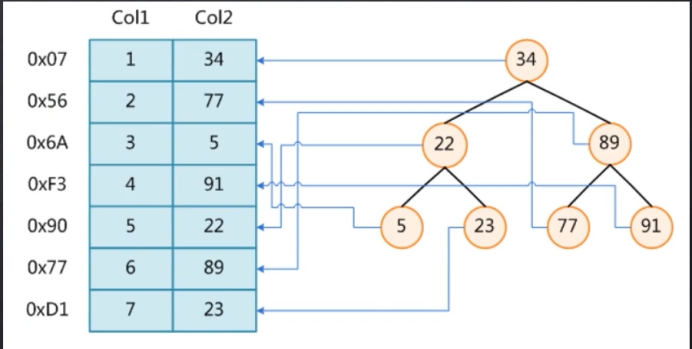
二叉树弊端
容易形成链表结构,当key值呈逐步增长时,会形成链表
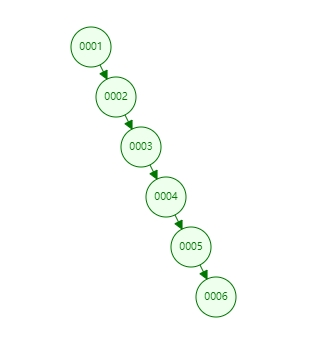
如果数据量大的时候,二叉树树结构会非常高,如果遇到数据刚好在最底层,需要进行大量的I/O,导致效率低下
1.2 红黑树
红黑树由二叉树演变而来,红黑树会自动平衡最顶层的key值,从而保证树结构左边的key值永远小于右边的key值
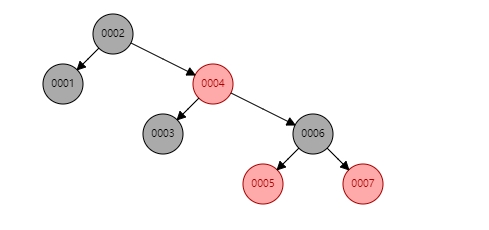
优点(相对二叉树):避免了树结构呈链表形式扩展
缺陷:和二叉树类似,当数据量很大时,查询的数据不理想,会造成很高的磁盘IO,依然很耗费性能。
1.3 hash表
将key值进行一次hash运算,然后放入hash表中,hash表的查找效率很高,进行相等查询时,hash表结构只需要查询一次就能查询到数据,所以效率很高。
弊端: hash表不能进行范围查询,所以一旦有范围查询时,hash表的索引将会失效,导致效率低下,所以说hash表的索引结构有局限性

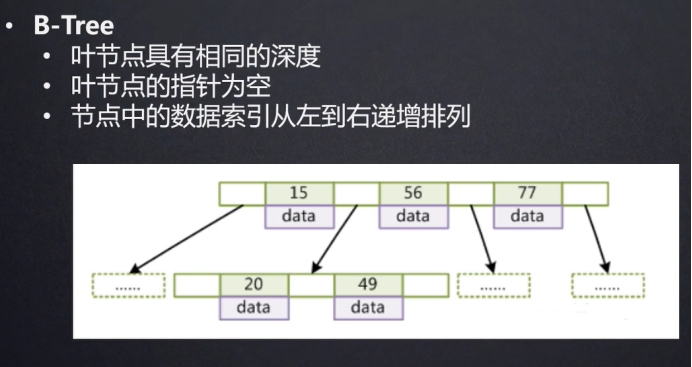
1.4 b-tree
B树叶节点默认是16K,只存Key值,不存对应的vule指针,叶节点中的数据索引从左向右递增排列
优点:解决了红黑树中,树深度的问题
缺点:没办法高效的查询范围数据。比如查询key大于20的数据,会经过多次查询,然后将数据放入集合。性能损耗及查询效率不高。
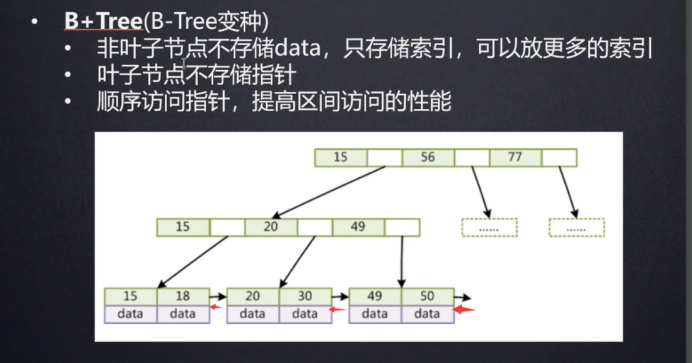
1.5 B+树
非叶子节点大小默认为16K,非叶子节点不存储data(数据对应内存地址),只存储索引和指针。一个long型的key占8B(8个字节),指针占6B。一个索引对应一个指针,指针指向下一个子节点(可以是非叶子节点,也可能是叶子节点)。
叶子节点不存储指针,存储key值和data值(大概占1K)。每个叶子节点之间,都有双向指针,指向前一个(或后一个)节点得地址,这样大大提高了区间访问的性能
计算B+树索引高效查询数据的量(以上图三个节点为例): 第一个节点16K/14B =1170 第二个节点16K/14b=1170 第三个节点 16K/1K = 16 。总计数量≈1170X1170X16 = 21902400 一般mysql会把第一个节点放置到内存中,这样最多进行2到 3次I/O就能准确的查询到数据,大大提升了查询效率。 当数据量为亿级数据时,需要采用分库分表的优化方式了。
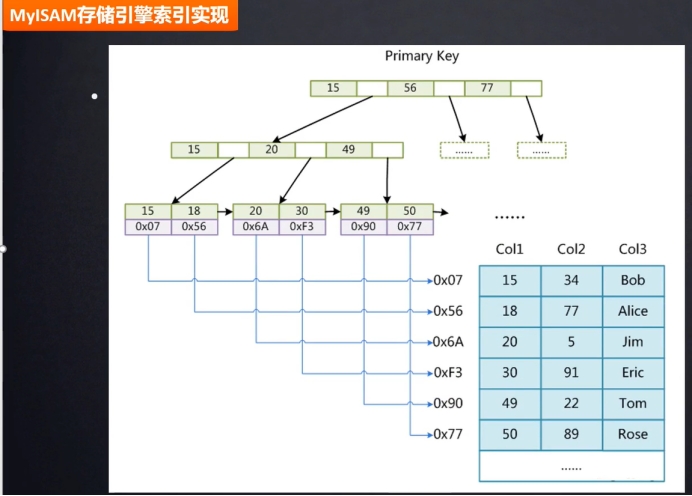
三 存储引擎
聚集索引:索引的键值和数据存放到一块。键值数据不分离->INNORDB存储引擎实现
非聚集索引:索引的键值和数据不放在一块。键值-数据分离->MyISAM
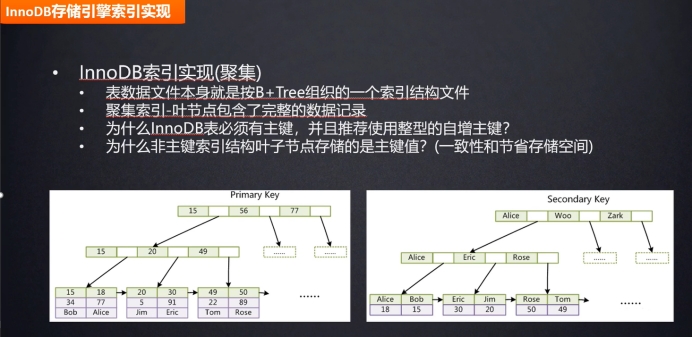
问:为什么innnordb中,表必须有主键,并且推荐使用整型的自增主键?
答: Innordb中,数据底层存放通过b+树实现,数据都存放在底层,和索引关联的。主键默认会建立一个索引.
如果使用整型的自增主键,数据在加入的时候,会自动向后加,不会破坏中间的结构。如果使用字符串类型的主键,会在数据加入的时候将字符串转为ASC码,然后比较ASC码大小,进行插入,会破坏索引结构
- 本文标签: Java mysql
- 本文链接: https://www.tianyajuanke.top/article/34
- 版权声明: 本文由吴沛芙原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权
热门推荐









相关文章
近期评论
-
来自: Linux安装python环境

-
来自: 留言板

-
来自: Linux环境安装mysql、git、docker、nginx

-
来自: vue 阿里云服务端签名直传

-
来自: Spring Session Data Redis
