
Python基础(篇三)
温馨提示:
本文最后更新于 2022年10月27日,已超过 1,374 天没有更新。若文章内的图片失效(无法正常加载),请留言反馈或直接联系我。
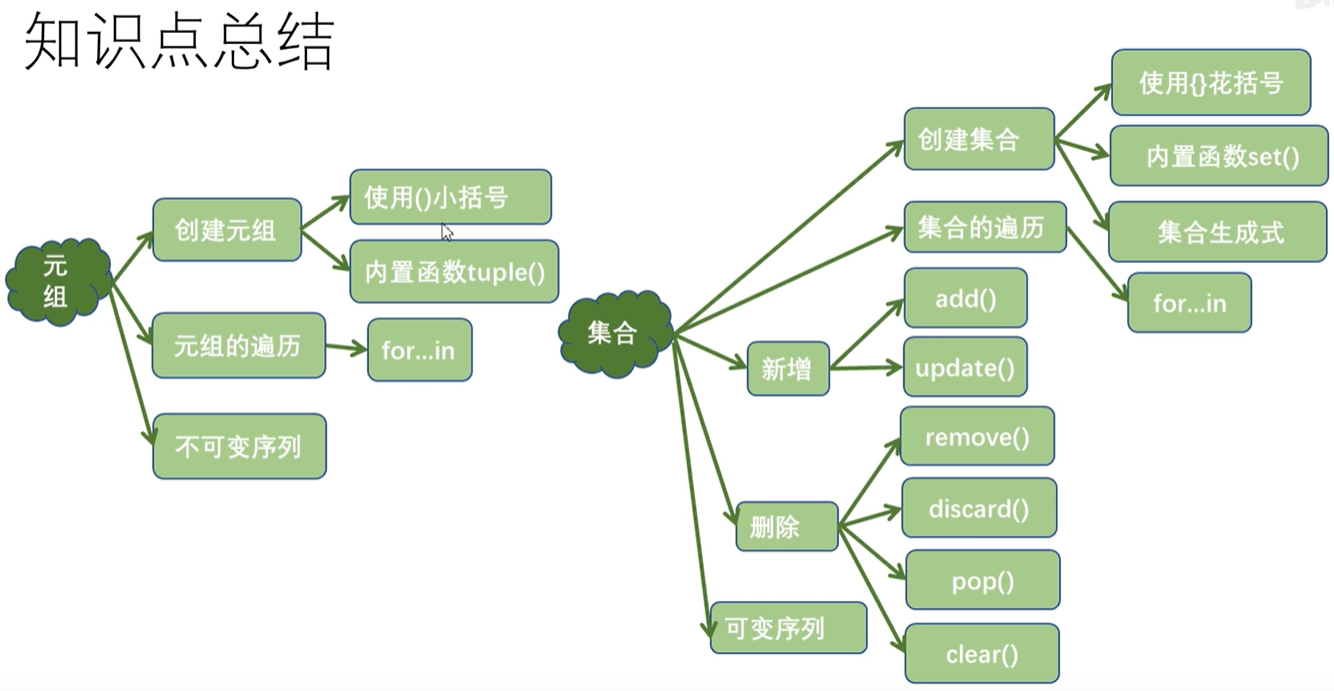
六. 元组和集合
1. 什么是元组

2. 元组的创建方式
使用小括号
t = ('hello','python')使用内置函数tuple()
t = tuple(('hello','python'))只包含一个元组的元素需要使用逗号和小括号
t = ('python',)为什么要将元组设计成不可变序列
在多任务环境下,同时操作对象时不需要加锁
因此,在程序中尽量使用不可变序列
注意事项:
元组中存储的是对象的引用
a)如果元组中对象本身不可对象,则不能再引用其它对象b)如果元组中的对象是可变对象,则可变对象的引用不允许改变,但数据可以改变
t = (10,{"name":"张三"},50)
print(t)
# t[1] = 100 #不能修改元组中的元素
t[1]["age"] = 18 #可以修改元组中可变元素的值 会抛出异常
print(t)
"""元组中的元素指向地址不可变化。意味着我们不能修改元组中的元素
但是可变元素,其值在修改后,内存地址不会发生变化,所以可以修改元组中可变元素的值
"""
3. 元组的遍历
for item in t:
print(item)
4. 什么是集合
- 底层数据采用的hash表
- Python语言提供的内置数据结构
- 与列表、字典—样都属于可变类型的序列
- 集合是没有value的字典
5. 集合的创建
- 使用{}
- 使用内置函数set()
s={1,3,5,7,1,4,5,2,3,6,78,1,54} #集合中的元素不可重复 直接定义
print(s)
s1 = set(range(1,10)) #使用内置函数
print(s1)
s2 = set({}) #创建空集合
print(s2)
6. 集合的增删改查操作
- 集合元素的判断操作
- in或not in
- 集合元素的新增操作
- 调用add()方法,一次添中一个元素
- 调用update()方法至少添中一个元素
- 集合元素的删除操作
- 调用remove()方法,一次删除一个指定元素,如果指定的元素不存在抛出KeyError
- 调用discard()方法,一次删除一个指定元素,如果指定的元素不存在不抛异常
- 调用pop()方法,一次只删除一个任意元素
- 调用clear()方法,清空集合
s={1,3,5,7,1,4,5,2,3,6,78,1,54} #集合中的元素不可重复 直接定义
print(2 in s)
print(22 not in s)
print(2 not in s)
s.add("asda") #添加单个元素
s.update(["asd","ss","Aaaa"]) #批量添加元素 可以添加列表 元组
s.remove("asda") # 移除指定元素,如果不存在移除的元素,则会抛出异常 KeyError
s.discard("Aaaa") # 移除指定元素,如果不存在移除的元素,不做操作
print(s)
s.pop() #随机删除元素
print(s)
s.clear() #清空集合
for item in s: #遍历集合
print(item)
集合之间的关系
- 两个集合是否相等
- == 或 !=进行判断
- 一个集合是否是另一个集合的子集
- issubset 进行判断
- 几个集合是否时另一个集合的超集
- issuberset 进行判断
- 两个集合是否没有交集
- isdisjoint进行判断
l1 = {1,2,3,4,45,88,112}
l2 = {1,2,3,4}
l3 = {3,4}
l4 = {33,44}
print(l1==l2) #判断集合是否相等,判断元素是否相等
print(l2.issubset(l1)) #判断集合是否是另一个集合的子集
print(l2.issubset(l3)) #判断集合是否是另一个集合的子集
print(l1.issuperset(l2)) #判断一个集合是否是另一个集合的超集(一个集合包含另一个集合的所有元素)
print(l1.isdisjoint(l2)) #判断两个集合是否没有交集 有交集为False 没有交集为true
print(l3.isdisjoint(l4)) #判断两个集合是否没有交集 有交集为False 没有交集为true
集合中的数学操作
交集 并集 差集 对称差集
s1 = {10,12,20,30,50}
s2 = {20,30,50,55}
print(s1.intersection(s2)) #交集
print(s1 & s2) #交集
print(s1.union(s2)) #并集
print(s1 | s2) #并集
print(s1.difference(s2)) #差集
print(s1 - s2) #差集
print(s1.symmetric_difference(s2)) #对称差集
print(s1 ^ s2) #对称差集
7. 集合生成式
生成集合的公式
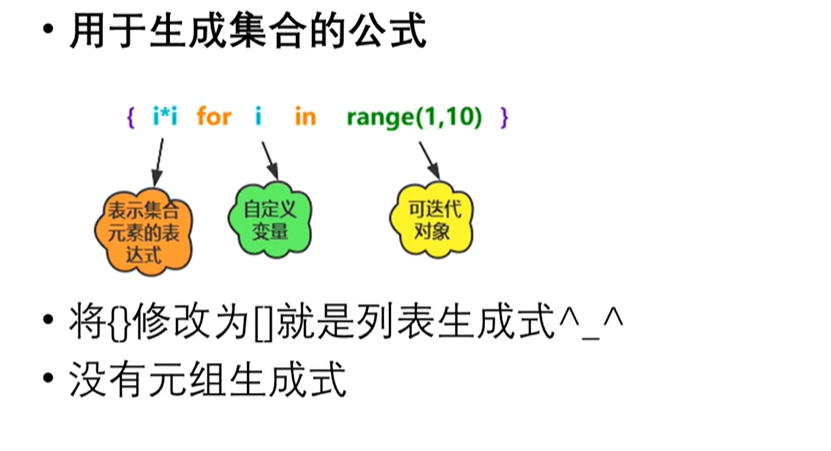
lst = {i for i in range(1,10)}
print(lst)
列表,字典,元组,集合总结
| 数据结构 | 是否可变 | 是否重复 | 是否有序 | 定义符号 |
|---|---|---|---|---|
| 列表(list) | 可变 | 可重复 | 有序 | [] |
| 元组(tuple) | 不可变 | 可重复 | 有序 | key不可重复 |
| 字典(dict) | 可变 | key不能重复 value可以重复 | 无序 | {key:value} |
| 集合(set) | 可变 | 不可重复 | 无序 | {} |
七. 字符串
在Python中字符串是基本数据类型,是一个不可变的字符序列
1.字符串的驻留机制
- 描述:仅保存一份相同且不可变字符串的方法,不同的值被存放在字符串的驻留池中,Python的驻留机制对相同的字符串只保留一份拷贝,后续创建相同字符串时,不会开辟新空间,而是把该字符串的地址赋给新创建的变量
- 驻留机制的几种情况(交互模式)
- 字符串的长度为0或1时
- 符合标识符的字符串
- 字符串只在编译时进行驻留,而非运行时
- [-5,256]之间的整数数字
- sys中的intern方法强制2个字符串指向同一个对象
- PyCharm对字符串进行了优化处理
- 字符串驻留机制的优缺点
- 当需要值相同的字符串时,可以直接从字符串池里拿来使用避免频繁的创建和销毁,提升效率和节约内存,因此拼接字符串和修改字符串是会比较影响性能的。
- 在需要进行字符串拼接时建议使用str类型的join方法,而非+ ,因为join()方法是先计算出所有字符中的长度,然后再拷贝,只new一次对象,效率要比"+"效率高
2.字符串的常用操作
查询操作
| 方法名称 | 作用 |
|---|---|
| index() | 查找子串substr第一次出现的位置,如果查找的子串不存在时,则抛出ValueError |
| rindex() | 查找子串substr最后一次出现的位置,如果查找的子串不存在时,则抛出ValueErrorfind() |
| find() | 查找子串substr第一次出现的位置,如果查找的子串不存在时,则返回-1 |
| rfind() | 查找子串substr最后一次出现的位置,如果查找的子串不存在时,则返回-1 |
s1 = "hello,hello"
print(s1.index("ll")) #查询字符串第一次出现的位置,不存在会抛出异常
print(s1.find("ll")) #查询字符串第一次出现的位置,不存在返回-1
print(s1.rindex("ll")) #查询字符串最后一次出现的位置,不存在会抛出异常
print(s1.rfind("ll")) #查询字符串最后一次出现的位置,不存在返回-1
# print(s1.index("ss")) #ValueError: substring not found
print(s1.find("ss")) #-1
# print(s1.rindex("Ss")) #ValueError: substring not found
print(s1.rfind("Ss")) #-1
字符串大小写转换
| 方法名称 | 作用 |
|---|---|
| upper() | 把字符串中所有字符都转成大写字母 |
| lower() | 把字符串中所有字符都转成小写字母 |
| swapcase() | 把字符串中所有大写字母转成小写字母,把所有小写字母都转成大写字母 |
| capitalize() | 把第一个字符转换为大写,把其余字符转换为小写 |
| title() | 把每个单词的第一个字符转换为大写,把每个单词的剩余字符转换为小写 |
"""使用字符串的转换功能,会生成一个新的字符串对象"""
s = "hello,PyThon 哈哈"
s1 = s.upper() #将字符串字母全部大写
print(s1)
s2 = s.lower() #将字符串字母全部转为小写
print(s2)
s3 = s.swapcase() #将大写字母转为小写字母,小写字母转为大写字母
print(s3)
s4 = s.capitalize() #将第一个字符串转为大写,其余转为小写
print(s4)
s5 = s.title() #将每个单词第一个转为大写,其余为小写
print(s5)
字符串对齐操作
| 方法名称 | 作用 |
|---|---|
| center() | 居中对齐,第1个参数指定宽度,第2个参数指定填充符,第2个参数是可选的,默认是空格,如果设置宽度小于实际宽度则则返回原字符串 |
| ljust() | 左对齐,第1个参数指定宽度,第2个参数指定填充符,第2个参数是可选的,默认是空格如果设置宽度小于实际宽度则则返回原字符串 |
| rjust() | 右对齐,第1个参数指定宽度,第2个参数指定填充符,第2个参数是可选的,默认是空格如果设置宽度小于实际宽度则则返回原字符串 |
| zfil1() | 右对齐,左边用0填充,该方法只接收一个参数,用于指定字符串的宽度,如果指定的宽度小于等于字符串的长度,返回字符串本身 |
s = "hello,python"
print(s.center(20,"*")) #填充字符*到20个字符。居中展示
print(s.center(10,"*")) #填充字符*到10个字符,如果原字符长度大于10,则返回原字符串
print(s.ljust(20,"*")) #填充字符*到20个字符。左对齐
print(s.ljust(10,"*")) #填充字符*到10个字符。如果原字符长度大于10,则返回原字符串
print(s.rjust(20,"*")) #填充字符*到20个字符。右对齐
print(s.rjust(10,"*")) #填充字符*到10个字符。如果原字符长度大于10,则返回原字符串
print(s.zfill(20)) #填充字符串0到20个字符,右对齐
print(s.zfill(10)) #填充字符串0到10个字符,如果原字符长度大于10,则返回原字符串
print('-9528'.zfill(10)) #填充字符串0到10个字符,右对齐(如果带-号,则负号在最左边)
字符串拆分
| 方法名称 | 作用 |
|---|---|
| split() | 从字符串的左边开始劈分,默认的劈分字符是空格字符串,返回的值都是一个列表 |
| split() | 以通过参数sep指定劈分字符串是的劈分符 |
| split() | 通过参数maxsplit指定劈分字符串时的最大劈分次数,在经过最大次劈分之后,剩余的子串会单独做为一部分 |
| rsplit() | 从字符串的右边开始劈分,默认的劈分字符是空格字符串,返回的值都是一个列表 |
| rsplit() | 以通过参数sep指定劈分字符串是的劈分符 |
| rsplit() | 通过参数maxsplit指定劈分字符串时的最大劈分次数,在经过最大次劈分之后,剩余的子串会单独做为一部分 |
字符串判断
| 方法名称 | 作用 |
|---|---|
| isidentifier() | 判断指定的字符串是不是合法的标识符 |
| isspace() | 判断指定的字符串是否全部由空白字符组成(回车、换行,水平制表符) |
| isalpha() | 判断指定的字符串是否全部由字母组成 |
| isdecimal() | 判断指定字符串是否全部由十进制的数字组成 |
| isnumeric() | 判断指定的字符串是否全部由数字组成 |
| isalnum() | 判断指定字符串是否全部由字母和数字组成 |
s = "hello,python"
print(s.isidentifier()) #英文点 逗号属于不合法标识
print("hello,python".isidentifier())
print("\t".isspace()) #是否全部由空白字符串组成
print("asdasd".isalpha()) #判断字符串是否全部由字母组成
print("尼玛".isalpha()) #判断字符串是否全部由字母组成
print("1254.255".isdecimal()) #判断指定的字符串是否全部由十进制的数字组成
print("1254".isdecimal()) #判断指定的字符串是否全部由十进制的数字组成
print("1254".isnumeric()) #判断指定的字符串是否全部由数字组成
print("1254".isalnum()) #判断指定的字符串是否全部由数字组成
字符串替换和合并
| 功能 | 方法名称 | 作用 |
|---|---|---|
| 字符串替换 | replace() | 第1个参数指定被替换的子串,第2个参数指定替换子串的字符串,该方法返回替换后得到的字符串,替换前的字符串不发生变化,调用该方法时可以通过第3个参数指定最大替换次数 |
| 字符串合并 | join() | 将列表或元组中的字符串合并成一个字符串 |
s1 = "hello python"
print(s1.replace("python","java")) #替换指定字符
print(s1.replace("l","L",1)) #替换指定字符,并指定替换个数
lst = ["天","王","盖","地","虎"]
print(",".join(lst)) #将列表转为字符串,并添加指定字符
print("".join(lst)) #将列表转为字符串
lst2 = [item for item in s1]
print(lst2)
3.字符串的比较
- 运算符: >,>=,<,<=,==,!=
- 比较规则:首先比较两个字符串中的第一个字符,如果相等则继续比较下一个字符,依次比较下去,直到两个字符串中的字符不相等时,其比较结果就是两个字符串的比较结果,两个字符串中的所有后续字符将不再被比较
- 比较原理:两上字符进行比较时,比较的是其ordinal value(原始值),调用内置函数ord可以得到指定字符的ordinal value。与内置函数ord对应的是内置函数chr,调用内置函数chr时指定ordinal value可以得到其对应的字符
"""比较的是原始得编码值"""
print("apple">"app")
print("apple">"appzz")
"""
==和is的区别
==比较的值是否相同
is比较的是id是否相同
"""
a=b="python"
c="python"
d="".join("python")
print(a == b)
print(a is b)
print(a == c )
print(a is c )
print(a == d)
print(id(a),id(d),a is d)
4.字符串的切片操作
s = "hello python"
print(s[-7::-1])
print(s[-6::1])
print(s[:6])
print(s[:6:2])
print(s[::2])
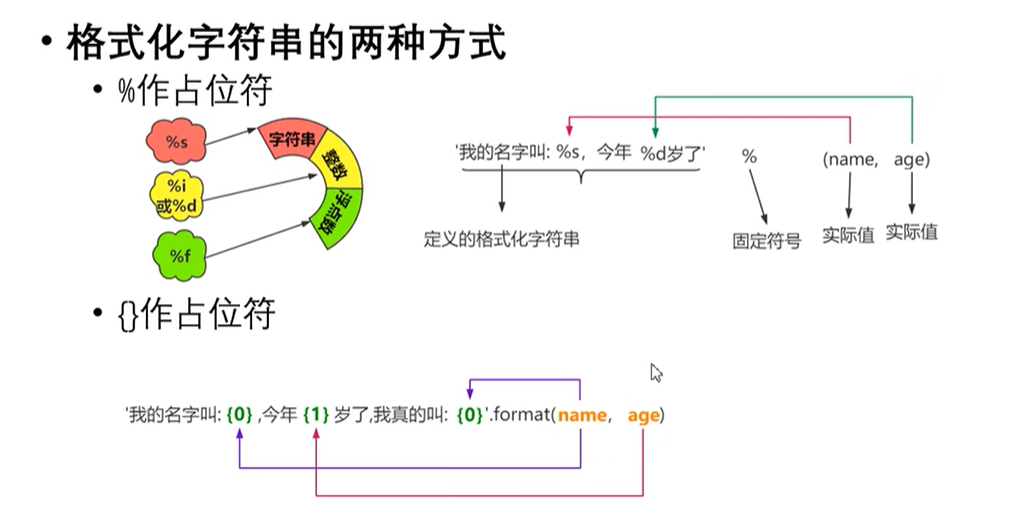
5.格式化字符串
#数字精度标识
print("%d" % 22)
print("%10d" % 22) #10代表的是宽度
print("%f" % 3.141596428) #浮点型占位数,默认保留6位
print("%.8f" % 3.141596428) #浮点型占位数,指定保留小位数。四舍五入
print("%18.8f" % 3.141596428) #浮点型占位数,指定宽度,指定保留小位数。四舍五入
print('{:.3}'.format(13.1415964285555)) #使用{}占位符,.3表示只保留三位数
print('{:.3f}'.format(13.1415964285555)) #使用{}占位符,.3f表示保留三位小数
print('{:20.3f}'.format(13.1415964285555)) #使用{}占位符,.3f表示保留三位小数 20表示宽度
6.字符串的编码转换
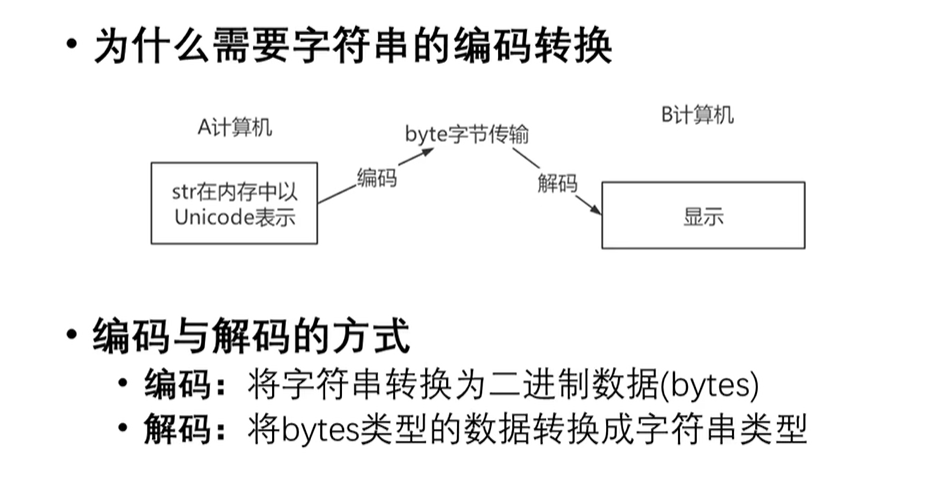
s = "你是我患得患失的梦"
print(s.encode(encoding="gbk")) #一个中文占两个字符
print(s.encode(encoding="utf8")) #一个中文占三个字符
print(bytes.decode(b'\xe4\xbd\xa0\xe6\x98\xaf\xe6\x88\x91\xe6\x82\xa3\xe5\xbe\x97\xe6\x82\xa3\xe5\xa4\xb1\xe7\x9a\x84\xe6\xa2\xa6',encoding="utf8"))
print(bytes.decode(b'\xc4\xe3\xca\xc7\xce\xd2\xbb\xbc\xb5\xc3\xbb\xbc\xca\xa7\xb5\xc4\xc3\xce',encoding="GBK"))
7.字符串总结
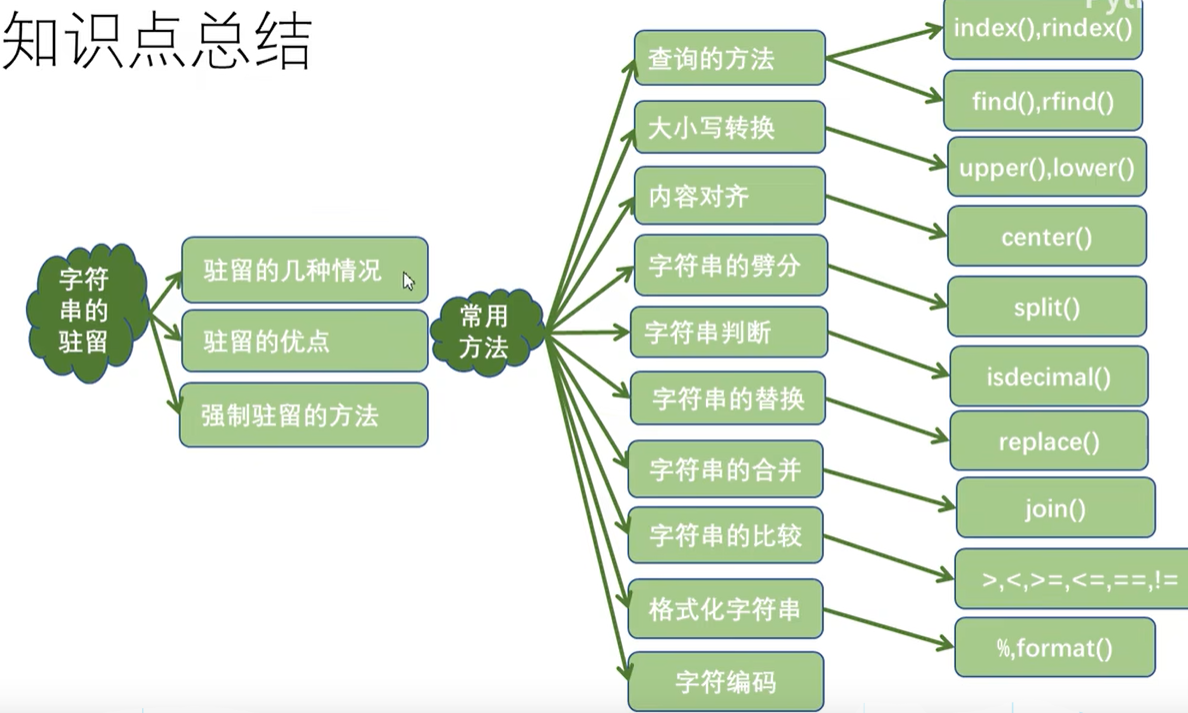
正文到此结束
- 本文标签: python
- 本文链接: https://www.tianyajuanke.top/article/44
- 版权声明: 本文由吴沛芙原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权
热门推荐









相关文章
近期评论
-
来自: Linux安装python环境

-
来自: 留言板

-
来自: Linux环境安装mysql、git、docker、nginx

-
来自: vue 阿里云服务端签名直传

-
来自: Spring Session Data Redis
